咨询电话: 027-88109788

GPU升级反遭骂!明明算力才是核心为何偏偏走向“堆料”道路?!
发布于 2025-09-28 02:00 阅读()
其浮点运算能力(FLOPS)并未如预期般实现指数级增长,反而逐渐陷入“堆料”困境。

若要打造真正的AI原生游戏,需同时攻克图形渲染、高性能计算与AI技术三大难关,绝非单纯依赖AI算力就能实现。

这款采用台积电3nm工艺的旗舰芯片,延续八核心设计却在架构与频率上实现突破。
配合Travis架构15%的IPC性能提升,理论单核性能可达3900分左右。
宣称能让手游光追帧率突破100帧,能效同时提升40%,对游戏玩九游体育家而言极具吸引力。

曝光的GeekBench 6跑分显示,天玑9500单核2485分、多核7321分的成绩明显异常。
测试时频率仅在3.1-3.5GHz之间,即便按此推算,4.21GHz状态下也仅能达到3000分出头。
业内推测,这可能是由于测试中Travis超大核未正常启动,转而由Alto大核承担性能输出所致。

智能手机受限于紧凑的机身结构,其主动散热系统的功率通常仅能维持在7W左右。

在相同功耗条件下输出更高性能,才能确保手机在游戏运行、视频处理及多任务操作等场景中保持流畅。
有效规避因设备发热引发的帧率下降与操作卡顿问题,而优异的能效比也已成为当前高端移动芯片的核心竞争优势。
放眼整个计算领域,CPU、GPU、ASIC与FPGA四大核心单元各有所长,共同构筑起算力世界的基石。
作为计算机“大脑”的CPU,基于冯·诺依曼架构,擅长指令解析、任务调度与逻辑判断,但其指令与数据共享存储和总线的设计,导致多数据处理效率较低。

CPU性能提升主要依赖时钟频率与内核数的增加,却也因此面临能耗过高、发热严重的问题,如今已逐渐触及性能瓶颈,算力发展开始向专用化方向倾斜。
GPU的崛起则源于其独特的并行架构。最初为图形渲染而生的它,凭借成百上千个小核心的协同工作,能高效处理海量重复性计算。
就像一群小学生共同完成简单任务,效率远超单个大学教授,如今,GPU的应用早已超越图形领域,在AI训练、科学计算、机器学习等场景中成为核心力量。
比如训练GPT等大型语言模型,用GPU仅需几天甚至几小时,CPU则可能需要数月。
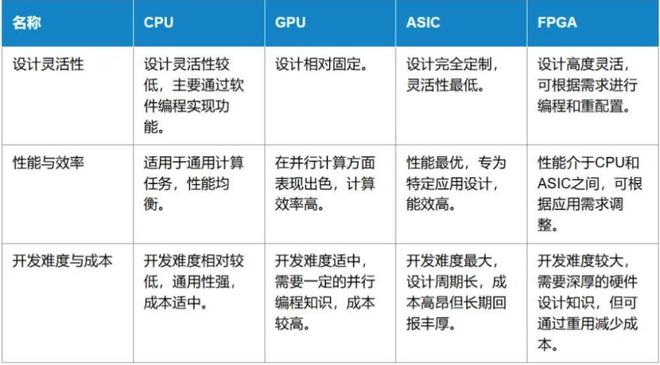
ASIC作为专用集成电路,如同服装界的私人定制,为特定任务量身打造电路结构。
但高定制性也意味着高研发成本与技术门槛,且设计完成后难以修改,灵活性不足。
FPGA则恰好弥补了这一缺陷,作为可现场编程的门阵列,它像一套智力积木。
用户可根据需求自行配置功能,虽在性能与能效上略逊于ASIC,却凭借出色的灵活性。

摩尔线%,AI智算业务占比飙升至77.63%,带动毛利率跃升至72.32%。
沐曦集成电路收入更是同比暴增1354.9%,达到7.42亿元,2025年一季度收入3.2亿元,已达前一年的43%。

寒武纪、海光信息等上市企业同样表现亮眼,寒武纪2025年一季度营收同比增长4230.22%,海光信息合同负债同比增长258.47%,彰显出市九游体育场对国产算力的强劲需求。
TrendForce集邦咨询预测,2025年中国AI服务器市场中外购芯片比例将从2024年的63%降至42%,而国产芯片占比有望提升至40%,与外购芯片几乎平分秋色。
不过,国产GPU仍面临生态建设的挑战,英伟达凭借近20年的软件生态积累,构建起难以撼动的壁垒,应用厂商迁移成本极高。
为此,国内企业纷纷布局全栈自主技术,沐曦自主研发MXMACA软件栈兼容CUDA生态,摩尔线程实现千亿门级SoC完整设计闭环,海光信息则计划通过收购中科曙光构建“芯片-服务器”完整生态链。

沐曦曦云C550 GPU、摩尔线计算卡先后完成与DeepSeek大模型的适配验证,加速“国产算力+国产大模型”闭环的形成。
行业也在探索超节点集群等新技术,通过优化数据传输路径,进一步提升计算效率,推动算力从单一芯片向“网、算、存”协同的方向发展。
从GPU的“堆料”争议到移动芯片的能效比拼,从四大计算单元的各司其职到国产算力的突围之路,算力世界的竞争从未停止。
未来,随着技术的不断融合与创新,我们必将迎来更加高效、灵活、智能的计算时代,而这场关乎未来的算力革命,才刚刚拉开序幕。
新闻资讯
 得力集团作为被告被上诉人的1起 TOP1
得力集团作为被告被上诉人的1起 TOP1 -
2 GPU升级反遭骂!明明算力才是 09-28
-
3
 探寻产业破局与生态进化密码20 09-28
探寻产业破局与生态进化密码20 09-28 -
4
 世界蚊子日:曾罕见的基孔肯雅热 09-28
世界蚊子日:曾罕见的基孔肯雅热 09-28 -
5
 实用新型专利维权规定是怎样的? 09-27
实用新型专利维权规定是怎样的? 09-27 -
6
 专利是企业生财的“富矿” 09-27
专利是企业生财的“富矿” 09-27 -
7
 大洋电机赴港上市遭遇专利狙击盈 09-27
大洋电机赴港上市遭遇专利狙击盈 09-27 -
8
 雅图高新过会:冯兆均兄弟控股超 09-27
雅图高新过会:冯兆均兄弟控股超 09-27 -
9
 朗科科技(300042) 09-27
朗科科技(300042) 09-27